Communication Backends, Raw performance benchmarking
08 Sep 2020 - Written by Edoardo HölzlDistributed learning requires workers to collaborate by swiftly sharing learned information with their “colleagues”. With the accelerating growth of model sizes in modern deep learning, this aspect gains even more importance.
MLBench supports both one and multiple processes per node, in addition to multi-node training. Communication between workers is crucial and will heavily affect performance, notably for communication bound training algorithms.
This blog post addresses and analyzes the raw performance of different communication backends on commodity communication hardware, used to transmit large arrays or tensors.
Communication Backends
Currently, MLBench supports 3 communication backends out of the box:
- MPI, or Message Passing Interface (using OpenMPI ‘s implementation)
- GLOO, available with PyTorch
- NCCL, high-speed connectivity between GPUs if used with correct hardware
Each backend presents its benefits and disadvantages, and is designed for specific use-cases, and those will be reflected in the results.
Differences
The following table illustrates the main differences between the 3 backends.
| Backend | Comm. Functions | Optimized for | Float32 | Float16 |
|---|---|---|---|---|
| MPI | All | CPU, GPU | Yes | No |
| GLOO | All (on CPU), broadcast & all-reduce (on GPU) | CPU | Yes | Yes |
| NCCL | broadcast, all reduce, reduce and all gather (on GPU) | GPU only | Yes | Yes |
As we can see, each has at least one main advantage, and must be used in specific cases.
It is also important to note that PyTorch (built from source) comes with NCCL and GLOO pre-installed, so it can be more convenient for a user to use one of those two. Otherwise, MPI needs to be compiled and installed on the machine.
Experiments
In order to evaluate the performance of communication backends, we have created a dummy task called Task 0,
which repeatedly sends random tensors of increasing sizes using an all reduce operation. This means that each worker shares his tensor with all other workers, and sums all the received tensors.
The time taken for this operation is accurately measured 100 times for each sent tensor on each worker, and averaged to get a statistically significant estimation of communication times.
To obtain those results, we have used the following hardware/software:
PyTorchdeep learning frameworkn1-standard-4(4 cores, 15GB RAM) machines on Google Cloud.NVIDIA® Tesla® T4(16GB GDDR6, Turing arch)
Results
As stated above, we compare the times of communication for different tensor types and backends.
There are 4 tensor type: Float16 & Float32 CPU or GPU tensors.
CPU vs GPU tensors?
MPI and GLOO support both CPU and GPU tensor communication, while NCCL only supports communication of GPU tensors. This is a great advantage, as CPU training is less costly and can be sped up using distributed training.
CPU
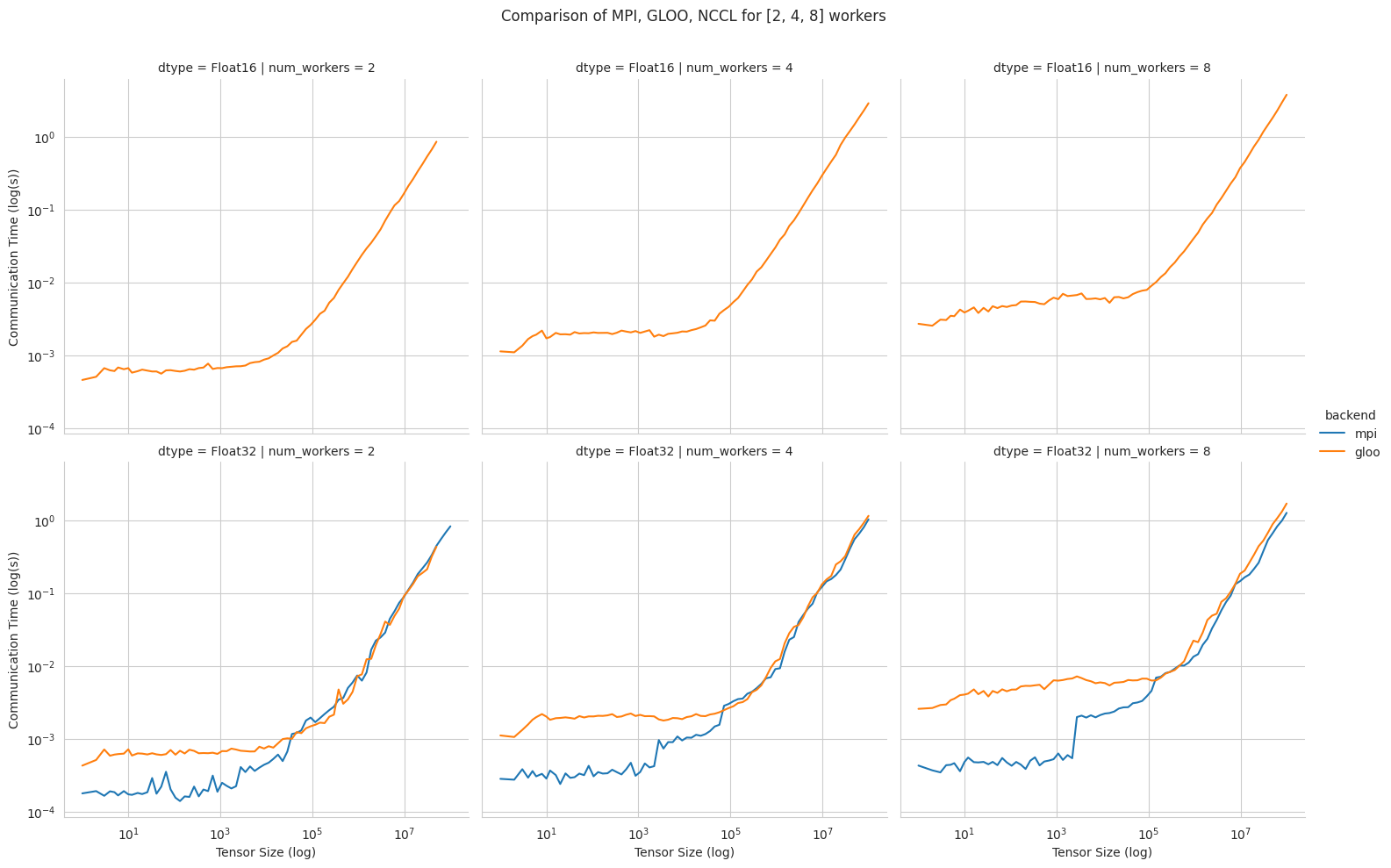
In the graph below, we compare the speeds taken to perform an all reduce operation between 2, 4 and 8 workers, of Float16 and Float32 CPU tensors.
Key differences
- GLOO supports
Float16communication, while Open MPI’s MPI implementation doesn’t. - MPI performs much better for low size tensors, for all numbers of workers.
- GLOO seems to be more sensitive to larger clusters: the increase in communication times is higher than MPI’s.
- For very large tensors, both seem to perform similarly, except as we add more workers (8 worker case).
GPU
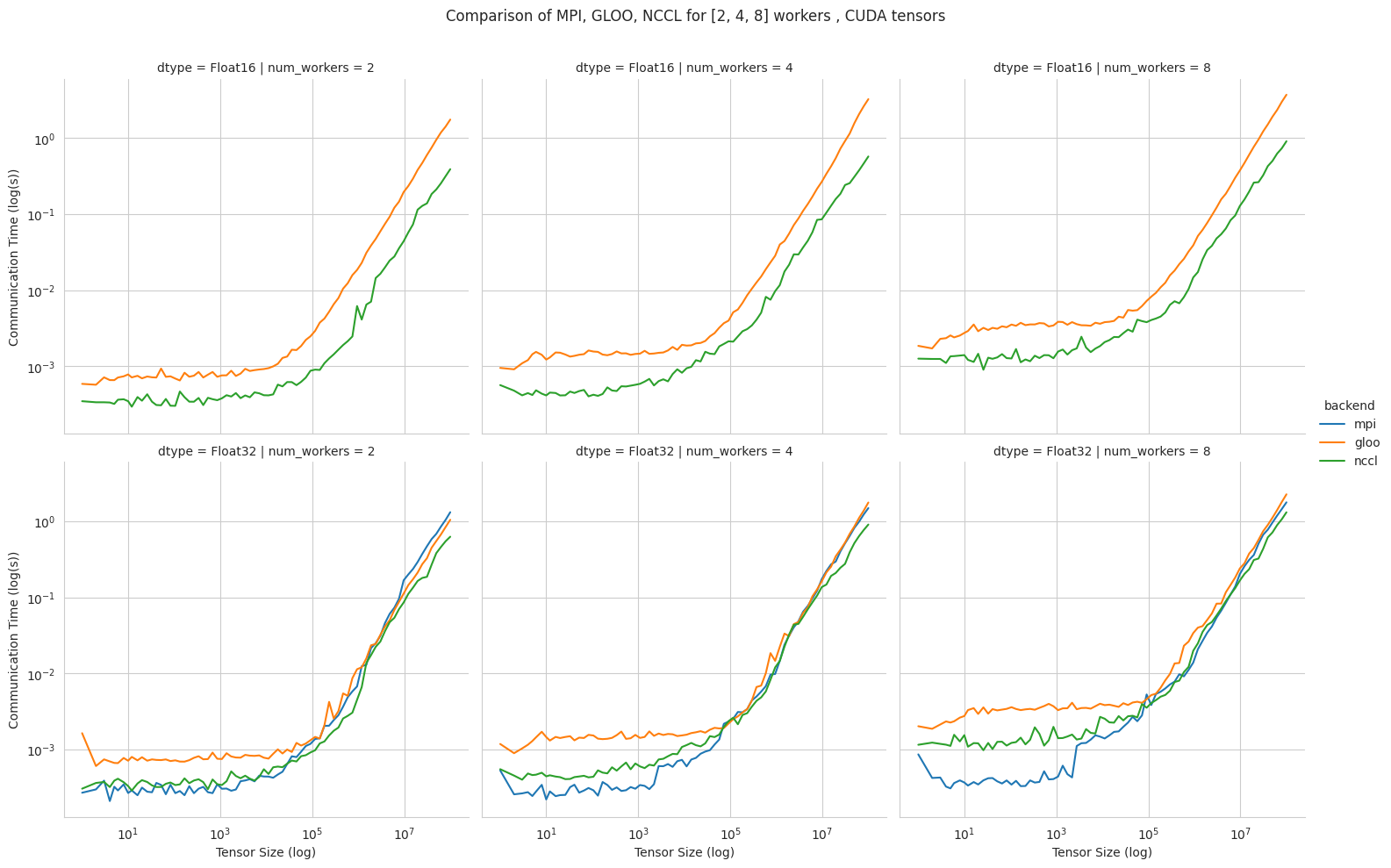
We now compare the speeds for GPU tensors. Here, we have the addition of NCCL in the comparison.
Key differences
- NCCL supports
Float16, and always performs better than GLOO. - MPI performs better than NCCL for small tensors (especially as we the cluster gets bigger)
- NCCL outperforms MPI and GLOO for very large tensors, regardless of cluster size.
Comparison
The results obtained clearly depict the different use cases for each backend, and how they could be used to fulfill one’s:
- GLOO has a main advantage of supporting
Float16communication of CPU tensors, and should then be used for that case. - MPI can be used with or without GPU, and performs better than its counterparts for small tensors. It should then be used for small tensor
communication in
Float32, and in all cases for CPU communication, also inFloat32. - NCCL can only be used with GPU acceleration, and is the best option if one wants to use
Float16. For largeFloat32tensors, it performs better than MPI.
How to run
The code for this benchmark is available here, and the docker image can be pulled using :
docker pull mlbench/pytorch-backend-benchmark:latest, and it can be used to benchmark any other backend.
To benchmark a custom backend, it must first be installed in the image. For that, simply modify the Dockerfile and rebuild the image.